Power BI
 share
share
 tweet
tweet
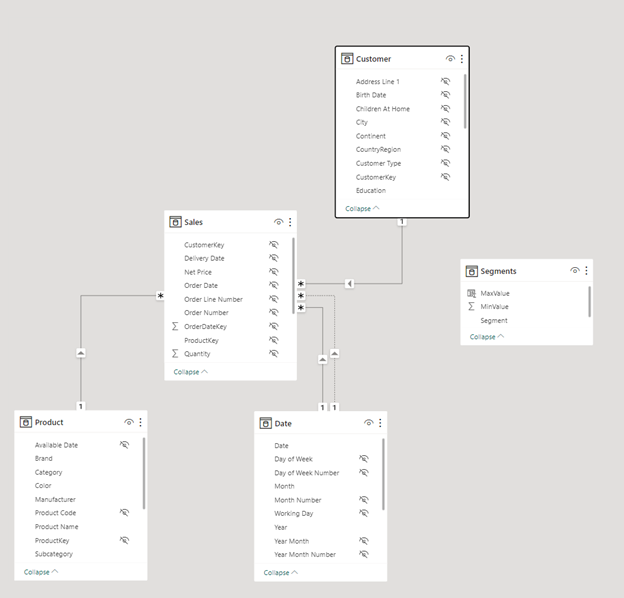
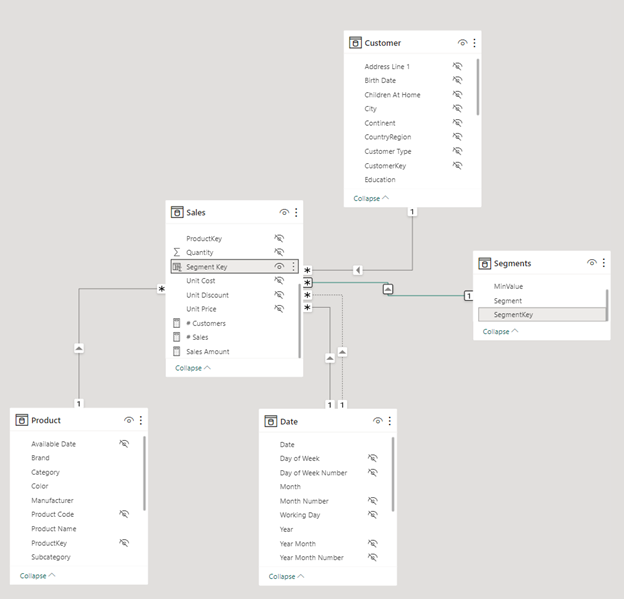
Bắt đầu bài viết này chúng ta sẽ có 1 Data Model như sau:
Ở đây chúng ta sẽ phân loại Unit Price theo các mức như sau.
Nếu Unit Price > 0 và <=100 thì sẽ là Very Low
Nếu Unit Price > 100 và <=200 thì sẽ là Low
Nếu Unit Price > 200 và <=500 thì sẽ là Medium
Nếu Unit Price > 500 và <=800 thì sẽ là High
Nếu Unit Price > 800 và <=3199.99 thì sẽ là Very high
Ở đây 3199.99 sẽ là giá trị Unit Price lớn nhất trong Data Sales của chúng ta.
Cụ thể thì mình đã tạo ra 1 Table Segments như hình dưới đây.
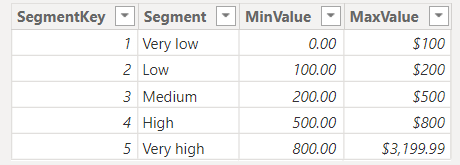
Như bạn có thể nhìn thấy là bảng Segments không hề có quan hệ gì với bảng Sales.
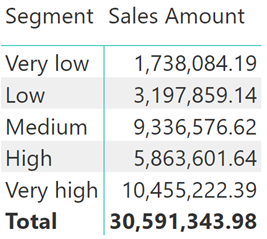
Vì thế khi ta kéo trường Segment vào Matrix thì chúng ta sẽ có kết quả như hình dưới đây.
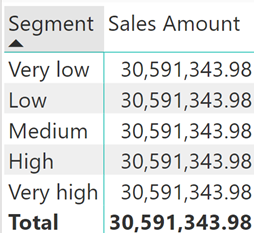
Lý do trả về kết quả như trên đó là vì bảng Segments và Sales không có mối quan hệ với nhau.
Vậy giờ làm thế nào để xử lý?
Giờ ta sẽ tạo ra 1 cột tên là Segment Key bên Table Sales. Sau đó ta sẽ kết nối mối quan hệ giữa 2 bảng Sales và Segment Key thông qua cột Segment Key này.
Dưới đây là công thức DAX được sử dụng để tạo nên cột Segment Key trên Table Sales.
Segment Key =
VAR Filter_Configuration =
FILTER(
Segments,
Sales[Unit Price] > Segments[MinValue] &&
Sales[Unit Price] <= Segments[MaxValue]
)
VAR Result =
CALCULATE(
DISTINCT(Segments[SegmentKey]),
Filter_Configuration
)
RETURN
Result
Mình sẽ giải thích công thức DAX trên 1 chút.
Đầu tiên là:
VAR Filter_Configuration =
FILTER(
Segments,
Sales[Unit Price] > Segments[MinValue] &&
Sales[Unit Price] <= Segments[MaxValue]
)
Với công thức trên thì chúng ta sẽ đi qua từng dòng trong Table Segments. Sau đó ta sẽ kiểm tra với điều kiện là Unit Price > MinValue và <= MaxValue.
Ở đây ta đang sử dụng Calculated Columns và Calculated Columns thì áp dụng Row Context. Vì thế Sales[Unit Price] sẽ đại diện cho từng dòng dữ liệu trong bảng Sales.
Tiếp theo là:
VAR Result =
CALCULATE(
DISTINCT(Segments[SegmentKey]),
Filter_Configuration
)
Với hàm trên thì bạn sẽ áp dụng điều kiện lọc như trên và lấy ra các giá trị không trùng lặp.
Điều này thì bạn có thể yên tâm vì chắc chắn chỉ có 1 giá trị kết quả trả về mà thôi vì các khoảng kết quả chúng ta có là không trùng lặp với nhau.
Đây là kết quả trả về:
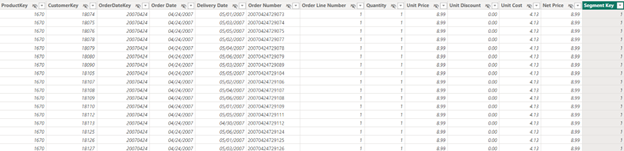
Giờ ta sẽ kết nối Data Model giữa bảng Sales và bảng Segments với nhau.
Và đây là kết quả chúng ta có:
Giờ ta sẽ đến với 1 bài toán khác như sau.
Ta có 1 Data Model như hình dưới đây.
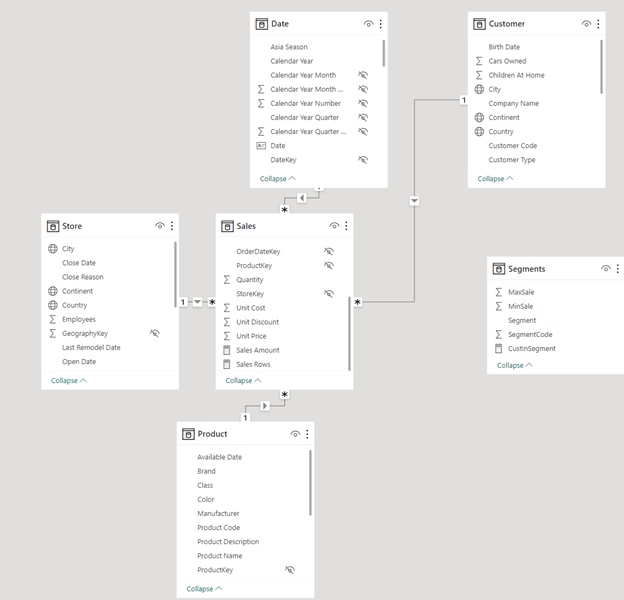
Chúng ta vẫn sẽ có bảng Segments không có bất kỳ kết nối nào với bảng Sales và Data Model.
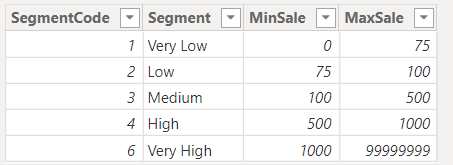
Ở bài này chúng ta không phân loại theo Unit Price nữa mà sẽ theo Sales Amount của từng khách hàng.
Nếu khách hàng đó có Sales Amount > 0 và <= 75 thì xếp hạng là Very Low
Nếu khách hàng đó có Sales Amount > 75 và <= 100 thì xếp hạng là Low
Nếu khách hàng đó có Sales Amount > 100 và <= 500 thì xếp hạng là Medium
Nếu khách hàng đó có Sales Amount > 500 và <= 1000 thì xếp hạng là High
Nếu khách hàng đó có Sales Amount > 1000 và <= 99999999 thì xếp hạng là Very High
Giờ ta sẽ cần viết 1 Measure để đếm xem mỗi năm có bao nhiêu khách hàng được xếp loại theo từng mức đã viết ở trên.
Ta sẽ viết 1 hàm DAX như sau.
Segment Customer Count =
SUMX(
Segments,
VAR Min_Value_For_Segments = Segments[MinSale]
VAR Max_Value_For_Segments = Segments[MaxSale]
VAR Result =
COUNTROWS(
FILTER(
Customer,
VAR Sales_Of_Customer = [Sales Amount]
RETURN
Sales_Of_Customer > Min_Value_For_Segments &&
Sales_Of_Customer <= Max_Value_For_Segments
)
)
RETURN
Result
)
Và đây là kết quả chúng ta đang có.
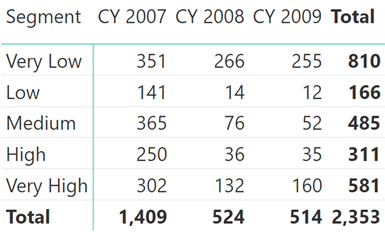
Giờ ta sẽ tạo thêm 1 Slicer Segment như sau và chọn như hình vẽ.
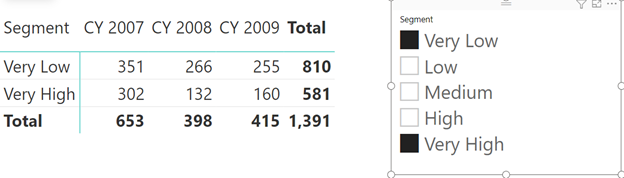
Bạn có thể thấy tất cả mọi dữ liệu đều đúng trừ dữ liệu Total theo dòng.
Ví dụ với Segment Very Low thì ta có 351 + 266 + 255 thì kết quả thu được phải là: 872 trong khi đó kết quả bạn thu được lại là 810?
Vậy tại sao ở đây kết quả lại là 810?
Như các bạn thấy là chúng ta đang lựa chọn 2 Segment là Very Low và Very High.
Với 2 tuỳ chọn này thì chúng ta có Min_Value_For_Segments và Max_Value_For_Segments nhận giá trị lần lượt sẽ là 0 và 99999999.
Tại sao?
Vì khi bạn chọn Slicer 2 mã Very Low và Very High thì khi đó bảng Segment sẽ chỉ có 2 dòng dữ liệu sau.

Chính vì thế nên kết quả Total theo từng dòng sẽ không hề chính xác.
Bạn phải biết rằng danh sách các khách hàng theo Segment thì có thể lặp lại hàng năm.
Vì thế với Total thì bạn sẽ phải tính toán lấy ra Số khách hàng từng năm xong sau đó mới cộng lại.
Để làm điều đó thì bạn cần phải sửa lại hàm DAX và thêm vào 1 chút như sau.
Segment Customer Count =
SUMX(
VALUES('Date'[Calendar Year]),
SUMX(
Segments,
VAR Min_Value_For_Segments = Segments[MinSale]
VAR Max_Value_For_Segments = Segments[MaxSale]
VAR Result =
COUNTROWS(
FILTER(
Customer,
VAR Sales_Of_Customer = [Sales Amount]
RETURN
Sales_Of_Customer > Min_Value_For_Segments &&
Sales_Of_Customer <= Max_Value_For_Segments
)
)
RETURN
Result
)
)
Và đây là kết quả cuối cùng.
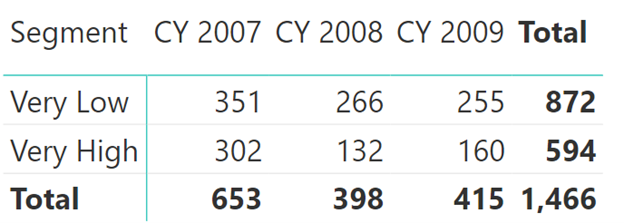
Như các bạn thấy là mình sẽ lồng thêm 1 hàm SUMX bên ngoài nữa để lặp qua từng năm (VALUES(‘Date’[Calendar Year]))
Với cách viết DAX như trên thì bạn sẽ thu được kết quả hoàn toàn chính xác như trên.
Bạn có thểm tham khoá khoá học Fast Track to POWER BI của ERX Việt Nam để có thể nắm bắt cách sử dụng Power BI 1 cách nhanh nhất tại địa chỉ sau:
https://erx.vn/fast-track-to-power-bi-dashboard-and-data-analysis-in-power-bi-903436838.html
File đính kèm bạn có thể download tại đây
.png)